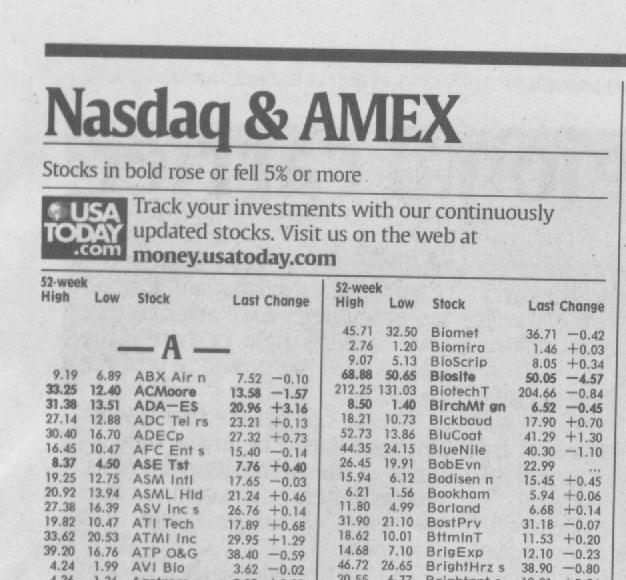
This text from USA Today was scanned at 200 dots per inch (dpi), 8 bit grayscale on a Primax Colorado 600p scanner and saved as a jpeg file at 75% quality using MGI PhotoSuite 8.06 (1998). The image contains serif and sans serif fonts in various sizes, some bold, and a logo. The text does not easily fit a language model but does have some redundancy by being organized into columns of letters and numbers and being alphabetically sorted. The JPEG files were saved with varying quality settings to introduce artifacts. The original bmp file is the raw image (lossless). Left click the link to view, right click to download.
8 bit grayscale, 200 dpi: bmp jpeg 75% jpeg 50% jpeg 25%

This test image contains a veriety of stylistic fonts and rotated text, some with an interfering background, that is easily read by humans but is difficult for optical character recognition software. The image above was scanned from a newspaper (slightly rotated). The image above is 24 bit color jpeg, 150 dpi, 75% quality. Other quality settings of the same image may be viewed below.
24 bit color, 150 dpi:
bmp
jpeg 75%
1 bit black and white, 200 dpi:
bmp
jpeg 75%
8 bit grayscale, 300 dpi:
bmp
jpeg 75%


The images above are CAPTCHAs used by Google. They are deliberately designed to be hard to read by OCR software.

This is a partial scan of a lap split sheet used in a footrace. Each pair of rows of numbers in this image was hand written by a different person.
150 dpi grayscale: bmp jpeg 75%
These images were posted on Jan. 7 2006 by Matt Mahoney
Results for OmniPage v14.0 (The current version is v15) by Yan King Yin, June 13, 2006. (link no longer works).
Results for Abbyy Fine Reader 5.0 (this version is about 2 years old. Current version is 8.0) by Yan King Yin, June 13, 2006. (link no longer works).
Results for Tesseract 2.03 (Mac) by Dave Osbourne, July 6, 2009.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
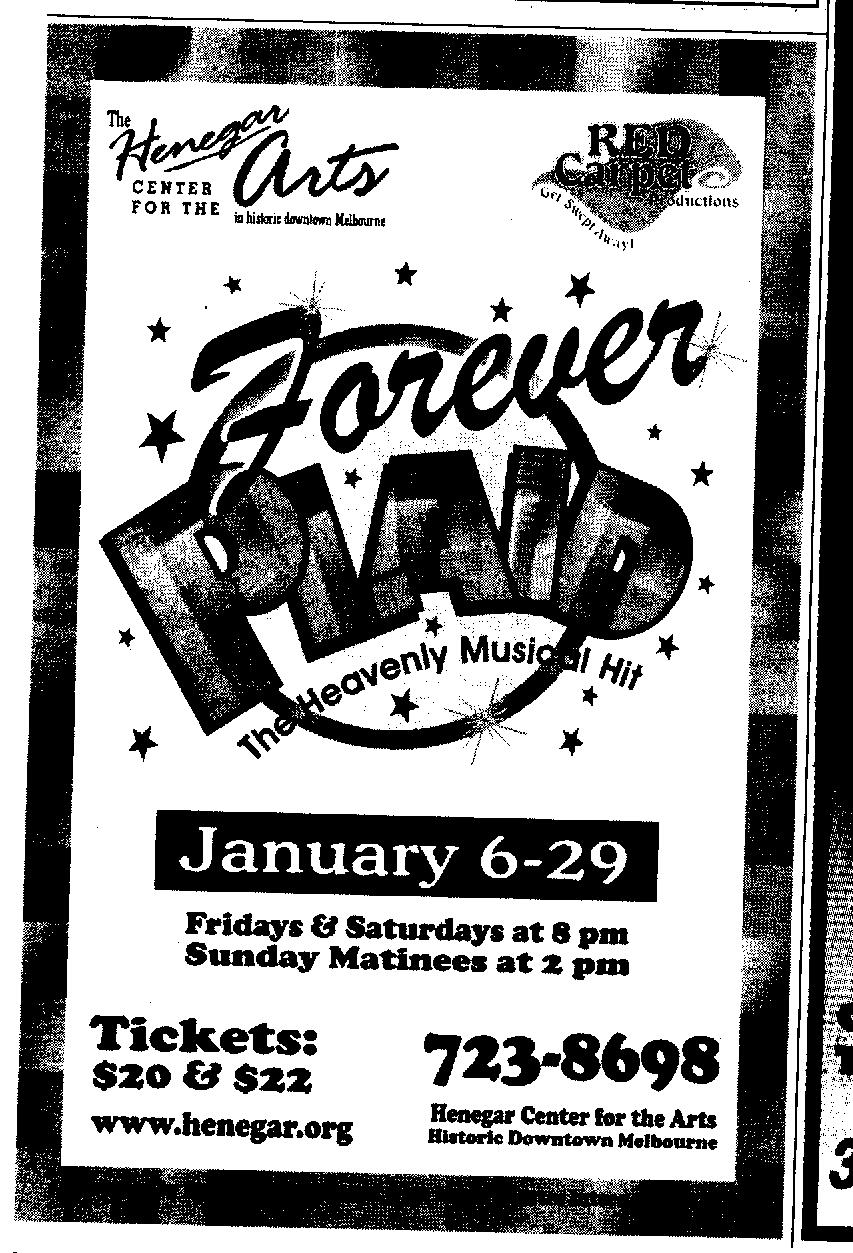{kind=link}
{kind=link}
{kind=link}
{kind=link}